Section 01. 내장 함수

숫자 함수

SELECT ABS(-343)
FROM dual;
SELECT ROUND(4.875, 1)
FROM Dual;
반올림
round(1234.12) ⇒ 1234
round(1234.1234, 2) ⇒ 1234.12
💡 보통은 반올림round 보다는 잘라냄 길이가 음수면, 해당 자리에서 반올림
💡 dual 테이블 : 간단한 연산 돌아갈 수 있게끔 하는 가상의 테이블
문자 함수

💡 다른 곳에서도 replace처럼 값을 바꿀 수 있지만 SQL이 제일 빠름
SQL > 서버 > 프론트
💡 count, substr은 많이 쓰임
문자열 뽑아내기
strsub(문자, 시작 위치, 길이)
left(문자, 길이)
right(문자, 길이)
날짜, 시간 함수
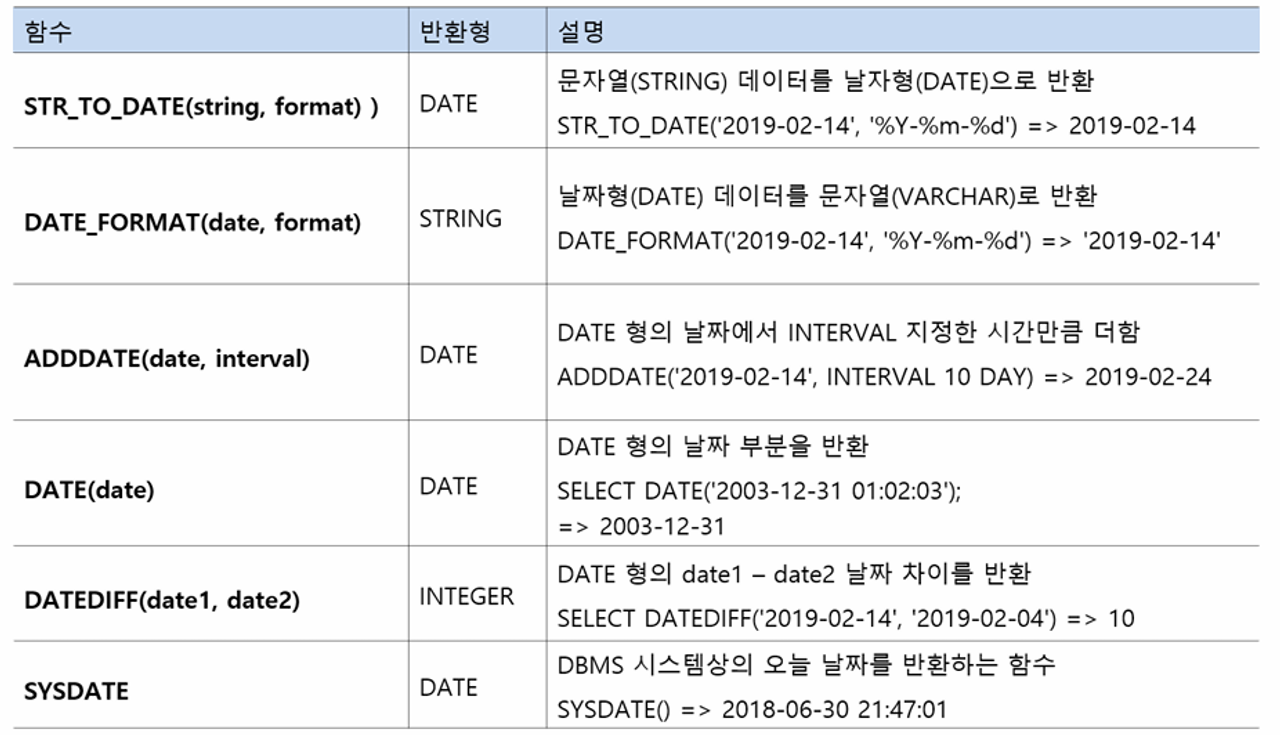
💡 date 형식 바꾸는 등 날짜 함수 자주 쓰임 데이터베이스에서 서버 혹은 프론트에 던져줄 때 시스템에 fit하게 맞춰서 던져줘야 함!
DATE_FORMAT

SELECT DATE_FORMAT(hire_ymd, '%Y-%m-%d')
FROM T ;
DATEDIFF(날짜1, 날짜2)
일 수 차이
날짜1 - 날짜2 이므로 순서 유의하기
So, 나중날짜 - 처음날짜 여야 양수
null 값 처리
null 값은 비교 연산자로 비교가 불가능함
null 값 연산 → null 값 반환
집계 함수 사용 시 주의!!
null이 포함된 행은 집계에서 아예 빠짐
해당되는 행이 하나도 없을 경우, sum, avg 함수의 결과는 null
count 함수의 결과는 0
IFNULL
SELECT IFNULL(freezer_yn, 'N') as freezer_yn
행 번호 출력
내장 함수는 아니지만 자주 사용 됨 → 요새는 interval이 생겨서 잘 안 씀
변수 이름 앞에 @ 기호 붙이며, 치환 문에는 set과 := 기호 사용
자료 일부분만 확인하여 처리할 때 유용
SET @seq:=0;
SELECT (@seq:=@seq+1) 순번,
custid,
name,
phone
FROM customer
WHERE @seq < 2;💡 seq 요새는 자주 안 쓰임
CASE WHEN
SELECT CASE WHEN 조건 THEN 참값 ELSE 거짓값 END
SELECT case when DATEDIFF(end_date, start_date) + 1 >= 30 then '장기 대여'
else '단기 대여' END as rent_type
FROM car_rental_company_rental_history
WHERE start_date LIKE '2022-09%'
ORDER BY history_id DESC;💡 AS 생략 가능
Section 02. 부속질의
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의
조인보다 필요 데이터만 찾아서 공급하는부속질의가 성능 더 good
주질의 (main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성

스칼라 부속질의 - SELECT 부속질의
부속질의 결과는 단일 행, 단일 열의 스칼라 값 반환
스칼라 값이 들어갈 수 있는 모든 곳에 사용 o
일반적으로 SELECT문, UPDATE SET절에서 사용
주질의, 부속질의 관계는 상관/비상관 모두
SELECT custid,
(SELECT name
FROM customer cs
WHERE cs.custid=od.custid),
SUM(saleprice)
FROM orders od
GROUP BY custid;
인라인 뷰 - FROM 부속질의
부속질의 결과는 다중 행, 다중 열이어도 됨
다만, 가상의 테이블인 뷰 형태 → 상관 부속질의 사용은 x
SELECT cs.name,
sum(od.saleprice) total
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) cs,
orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
중첩 질의 - WHERE 부속질의 = 술어 부속질의

SELECT orderid,
saleprice
FROM orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM orders);Section 03. 뷰
하나 이상의 테이블 합하여 만든 가상의 테이블
뷰 장점
- 편리성, 재사용성 : 자주 사용되는 복잡한 질의 미리 정의
→ 복잡한 질의 간단 작성
- 보안성 : 필요 데이터만 선별해서 보여줌, 중요한 질의 암호화o
- → 개인정보(주민번호) 등 민감한 정보 제외한 테이블 만들어 사용
- 독립성 : 미리 정의된 뷰를 일반 테이블처럼 사용 → 편리, 사용자가 필요한 정보만 가공
- → 원본 테이블 구조가 변해도 영향 x = 논리적 독립성 제공
뷰의 생성
CREATE VIEW 뷰이름 [열이름, , , ]
AS SELECT ~ FROM ~ WHERE ~
CREATE VIEW vw_customer
AS SELECT *
FROM customer
WHERE address LIKE '%대한민국%';
뷰의 수정
CREATE OR REPLACE VIEW vw_customer (custid, name, address)
AS SELECT custid, name, address
FROM customer
WHERE address LIKE '%영국%';
<aside> 💡 뷰는 수정 잘 안 함
</aside>
뷰의 삭제
04. SQL 고급
Section 01. 내장 함수
숫자 함수
SELECT ABS(-343)
FROM dual;
SELECT ROUND(4.875, 1)
FROM Dual;
반올림
round(1234.12) ⇒ 1234
round(1234.1234, 2) ⇒ 1234.12
<aside> 💡 보통은 반올림round 보다는 잘라냄 길이가 음수면, 해당 자리에서 반올림
</aside>
<aside> 💡 dual 테이블 : 간단한 연산 돌아갈 수 있게끔 하는 가상의 테이블
</aside>
문자 함수
<aside> 💡 다른 곳에서도 replace처럼 값을 바꿀 수 있지만 SQL이 제일 빠름 SQL > 서버 > 프론트
</aside>
<aside> 💡 count, substr은 많이 쓰임
</aside>
문자열 뽑아내기
strsub(문자, 시작 위치, 길이)
left(문자, 길이)
right(문자, 길이)
날짜, 시간 함수
<aside> 💡 date 형식 바꾸는 등 날짜 함수 자주 쓰임 데이터베이스에서 서버 혹은 프론트에 던져줄 때 시스템에 fit하게 맞춰서 던져줘야 함!
</aside>
DATE_FORMAT
SELECT DATE_FORMAT(hire_ymd, '%Y-%m-%d')
FROM T ;
DATEDIFF(날짜1, 날짜2)
일 수 차이
날짜1 - 날짜2 이므로 순서 유의하기
So, 나중날짜 - 처음날짜 여야 양수
null 값 처리
null 값은 비교 연산자로 비교가 불가능함
null 값 연산 → null 값 반환
집계 함수 사용 시 주의!!
null이 포함된 행은 집계에서 아예 빠짐
해당되는 행이 하나도 없을 경우, sum, avg 함수의 결과는 null
count 함수의 결과는 0
IFNULL
SELECT IFNULL(freezer_yn, 'N') as freezer_yn
행 번호 출력
내장 함수는 아니지만 자주 사용 됨 → 요새는 interval이 생겨서 잘 안 씀
변수 이름 앞에 @ 기호 붙이며, 치환 문에는 set과 := 기호 사용
자료 일부분만 확인하여 처리할 때 유용
SET @seq:=0;
SELECT (@seq:=@seq+1) 순번,
custid,
name,
phone
FROM customer
WHERE @seq < 2;
<aside> 💡 seq 요새는 자주 안 쓰임
</aside>
CASE WHEN
SELECT CASE WHEN 조건 THEN 참값 ELSE 거짓값 END
SELECT case when DATEDIFF(end_date, start_date) + 1 >= 30 then '장기 대여'
else '단기 대여' END as rent_type
FROM car_rental_company_rental_history
WHERE start_date like '2022-09%'
ORDER BY history_id DESC;
<aside> 💡 AS 생략 가능
</aside>
Section 02. 부속질의
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의
조인보다 필요 데이터만 찾아서 공급하는부속질의가 성능 더 good
주질의 (main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성
스칼라 부속질의 - SELECT 부속질의
부속질의 결과는 단일 행, 단일 열의 스칼라 값 반환
스칼라 값이 들어갈 수 있는 모든 곳에 사용 o
일반적으로 SELECT문, UPDATE SET절에서 사용
주질의, 부속질의 관계는 상관/비상관 모두
SELECT custid,
(SELECT name
FROM customer cs
WHERE cs.custid=od.custid),
SUM(saleprice)
FROM orders od
GROUP BY custid;
인라인 뷰 - FROM 부속질의
부속질의 결과는 다중 행, 다중 열이어도 됨
다만, 가상의 테이블인 뷰 형태 → 상관 부속질의 사용은 x
SELECT cs.name,
sum(od.saleprice) total
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) cs,
orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
중첩 질의 - WHERE 부속질의 = 술어 부속질의
SELECT orderid,
saleprice
FROM orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM orders);
Section 03. 뷰
하나 이상의 테이블 합하여 만든 가상의 테이블
뷰 장점
- 편리성, 재사용성 : 자주 사용되는 복잡한 질의 미리 정의
- → 복잡한 질의 간단 작성
- 보안성 : 필요 데이터만 선별해서 보여줌, 중요한 질의 암호화o
- → 개인정보(주민번호) 등 민감한 정보 제외한 테이블 만들어 사용
- 독립성 : 미리 정의된 뷰를 일반 테이블처럼 사용 → 편리, 사용자가 필요한 정보만 가공
- → 원본 테이블 구조가 변해도 영향 x = 논리적 독립성 제공
뷰의 생성
CREATE VIEW 뷰이름 [열이름, , , ]
AS SELECT ~ FROM ~ WHERE ~
CREATE VIEW vw_customer
AS SELECT *
FROM customer
WHERE address LIKE '%대한민국%';
뷰의 수정
CREATE OR REPLACE VIEW vw_customer (custid, name, address)
AS SELECT custid, name, address
FROM customer
WHERE address LIKE '%영국%';
<aside> 💡 뷰는 수정 잘 안 함
</aside>
뷰의 삭제
04. SQL 고급
Section 01. 내장 함수
숫자 함수
SELECT ABS(-343)
FROM dual;
SELECT ROUND(4.875, 1)
FROM Dual;
반올림
round(1234.12) ⇒ 1234
round(1234.1234, 2) ⇒ 1234.12
<aside> 💡 보통은 반올림round 보다는 잘라냄 길이가 음수면, 해당 자리에서 반올림
</aside>
<aside> 💡 dual 테이블 : 간단한 연산 돌아갈 수 있게끔 하는 가상의 테이블
</aside>
문자 함수
<aside> 💡 다른 곳에서도 replace처럼 값을 바꿀 수 있지만 SQL이 제일 빠름 SQL > 서버 > 프론트
</aside>
<aside> 💡 count, substr은 많이 쓰임
</aside>
문자열 뽑아내기
strsub(문자, 시작 위치, 길이)
left(문자, 길이)
right(문자, 길이)
날짜, 시간 함수
<aside> 💡 date 형식 바꾸는 등 날짜 함수 자주 쓰임 데이터베이스에서 서버 혹은 프론트에 던져줄 때 시스템에 fit하게 맞춰서 던져줘야 함!
</aside>
DATE_FORMAT
SELECT DATE_FORMAT(hire_ymd, '%Y-%m-%d')
FROM T ;
DATEDIFF(날짜1, 날짜2)
일 수 차이
날짜1 - 날짜2 이므로 순서 유의하기
So, 나중날짜 - 처음날짜 여야 양수
null 값 처리
null 값은 비교 연산자로 비교가 불가능함
null 값 연산 → null 값 반환
집계 함수 사용 시 주의!!
null이 포함된 행은 집계에서 아예 빠짐
해당되는 행이 하나도 없을 경우, sum, avg 함수의 결과는 null
count 함수의 결과는 0
IFNULL
SELECT IFNULL(freezer_yn, 'N') as freezer_yn
행 번호 출력
내장 함수는 아니지만 자주 사용 됨 → 요새는 interval이 생겨서 잘 안 씀
변수 이름 앞에 @ 기호 붙이며, 치환 문에는 set과 := 기호 사용
자료 일부분만 확인하여 처리할 때 유용
SET @seq:=0;
SELECT (@seq:=@seq+1) 순번,
custid,
name,
phone
FROM customer
WHERE @seq < 2;
<aside> 💡 seq 요새는 자주 안 쓰임
</aside>
CASE WHEN
SELECT CASE WHEN 조건 THEN 참값 ELSE 거짓값 END
SELECT case when DATEDIFF(end_date, start_date) + 1 >= 30 then '장기 대여'
else '단기 대여' END as rent_type
FROM car_rental_company_rental_history
WHERE start_date like '2022-09%'
ORDER BY history_id DESC;
<aside> 💡 AS 생략 가능
</aside>
Section 02. 부속질의
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의
조인보다 필요 데이터만 찾아서 공급하는부속질의가 성능 더 good
주질의 (main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성
스칼라 부속질의 - SELECT 부속질의
부속질의 결과는 단일 행, 단일 열의 스칼라 값 반환
스칼라 값이 들어갈 수 있는 모든 곳에 사용 o
일반적으로 SELECT문, UPDATE SET절에서 사용
주질의, 부속질의 관계는 상관/비상관 모두
SELECT custid,
(SELECT name
FROM customer cs
WHERE cs.custid=od.custid),
SUM(saleprice)
FROM orders od
GROUP BY custid;
인라인 뷰 - FROM 부속질의
부속질의 결과는 다중 행, 다중 열이어도 됨
다만, 가상의 테이블인 뷰 형태 → 상관 부속질의 사용은 x
SELECT cs.name,
sum(od.saleprice) total
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) cs,
orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
중첩 질의 - WHERE 부속질의 = 술어 부속질의
SELECT orderid,
saleprice
FROM orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM orders);
Section 03. 뷰
하나 이상의 테이블 합하여 만든 가상의 테이블
뷰 장점
- 편리성, 재사용성 : 자주 사용되는 복잡한 질의 미리 정의
- → 복잡한 질의 간단 작성
- 보안성 : 필요 데이터만 선별해서 보여줌, 중요한 질의 암호화o
- → 개인정보(주민번호) 등 민감한 정보 제외한 테이블 만들어 사용
- 독립성 : 미리 정의된 뷰를 일반 테이블처럼 사용 → 편리, 사용자가 필요한 정보만 가공
- → 원본 테이블 구조가 변해도 영향 x = 논리적 독립성 제공
뷰의 생성
CREATE VIEW 뷰이름 [열이름, , , ]
AS SELECT ~ FROM ~ WHERE ~
CREATE VIEW vw_customer
AS SELECT *
FROM customer
WHERE address LIKE '%대한민국%';
뷰의 수정
CREATE OR REPLACE VIEW vw_customer (custid, name, address)
AS SELECT custid, name, address
FROM customer
WHERE address LIKE '%영국%';
<aside> 💡 뷰는 수정 잘 안 함
</aside>
뷰의 삭제
04. SQL 고급
Section 01. 내장 함수
숫자 함수
SELECT ABS(-343)
FROM dual;
SELECT ROUND(4.875, 1)
FROM Dual;
반올림
round(1234.12) ⇒ 1234
round(1234.1234, 2) ⇒ 1234.12
<aside> 💡 보통은 반올림round 보다는 잘라냄 길이가 음수면, 해당 자리에서 반올림
</aside>
<aside> 💡 dual 테이블 : 간단한 연산 돌아갈 수 있게끔 하는 가상의 테이블
</aside>
문자 함수
<aside> 💡 다른 곳에서도 replace처럼 값을 바꿀 수 있지만 SQL이 제일 빠름 SQL > 서버 > 프론트
</aside>
<aside> 💡 count, substr은 많이 쓰임
</aside>
문자열 뽑아내기
strsub(문자, 시작 위치, 길이)
left(문자, 길이)
right(문자, 길이)
날짜, 시간 함수
<aside> 💡 date 형식 바꾸는 등 날짜 함수 자주 쓰임 데이터베이스에서 서버 혹은 프론트에 던져줄 때 시스템에 fit하게 맞춰서 던져줘야 함!
</aside>
DATE_FORMAT
SELECT DATE_FORMAT(hire_ymd, '%Y-%m-%d')
FROM T ;
DATEDIFF(날짜1, 날짜2)
일 수 차이
날짜1 - 날짜2 이므로 순서 유의하기
So, 나중날짜 - 처음날짜 여야 양수
null 값 처리
null 값은 비교 연산자로 비교가 불가능함
null 값 연산 → null 값 반환
집계 함수 사용 시 주의!!
null이 포함된 행은 집계에서 아예 빠짐
해당되는 행이 하나도 없을 경우, sum, avg 함수의 결과는 null
count 함수의 결과는 0
IFNULL
SELECT IFNULL(freezer_yn, 'N') as freezer_yn
행 번호 출력
내장 함수는 아니지만 자주 사용 됨 → 요새는 interval이 생겨서 잘 안 씀
변수 이름 앞에 @ 기호 붙이며, 치환 문에는 set과 := 기호 사용
자료 일부분만 확인하여 처리할 때 유용
SET @seq:=0;
SELECT (@seq:=@seq+1) 순번,
custid,
name,
phone
FROM customer
WHERE @seq < 2;
<aside> 💡 seq 요새는 자주 안 쓰임
</aside>
CASE WHEN
SELECT CASE WHEN 조건 THEN 참값 ELSE 거짓값 END
SELECT case when DATEDIFF(end_date, start_date) + 1 >= 30 then '장기 대여'
else '단기 대여' END as rent_type
FROM car_rental_company_rental_history
WHERE start_date like '2022-09%'
ORDER BY history_id DESC;
<aside> 💡 AS 생략 가능
</aside>
Section 02. 부속질의
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의
조인보다 필요 데이터만 찾아서 공급하는부속질의가 성능 더 good
주질의 (main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성
스칼라 부속질의 - SELECT 부속질의
부속질의 결과는 단일 행, 단일 열의 스칼라 값 반환
스칼라 값이 들어갈 수 있는 모든 곳에 사용 o
일반적으로 SELECT문, UPDATE SET절에서 사용
주질의, 부속질의 관계는 상관/비상관 모두
SELECT custid,
(SELECT name
FROM customer cs
WHERE cs.custid=od.custid),
SUM(saleprice)
FROM orders od
GROUP BY custid;
인라인 뷰 - FROM 부속질의
부속질의 결과는 다중 행, 다중 열이어도 됨
다만, 가상의 테이블인 뷰 형태 → 상관 부속질의 사용은 x
SELECT cs.name,
sum(od.saleprice) total
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) cs,
orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
중첩 질의 - WHERE 부속질의 = 술어 부속질의
SELECT orderid,
saleprice
FROM orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM orders);
Section 03. 뷰
하나 이상의 테이블 합하여 만든 가상의 테이블
뷰 장점
- 편리성, 재사용성 : 자주 사용되는 복잡한 질의 미리 정의
- → 복잡한 질의 간단 작성
- 보안성 : 필요 데이터만 선별해서 보여줌, 중요한 질의 암호화o
- → 개인정보(주민번호) 등 민감한 정보 제외한 테이블 만들어 사용
- 독립성 : 미리 정의된 뷰를 일반 테이블처럼 사용 → 편리, 사용자가 필요한 정보만 가공
- → 원본 테이블 구조가 변해도 영향 x = 논리적 독립성 제공
뷰의 생성
CREATE VIEW 뷰이름 [열이름, , , ]
AS SELECT ~ FROM ~ WHERE ~
CREATE VIEW vw_customer
AS SELECT *
FROM customer
WHERE address LIKE '%대한민국%';
뷰의 수정
CREATE OR REPLACE VIEW vw_customer (custid, name, address)
AS SELECT custid, name, address
FROM customer
WHERE address LIKE '%영국%';
<aside> 💡 뷰는 수정 잘 안 함
</aside>
뷰의 삭제
04. SQL 고급
Section 01. 내장 함수
숫자 함수
SELECT ABS(-343)
FROM dual;
SELECT ROUND(4.875, 1)
FROM Dual;
반올림
round(1234.12) ⇒ 1234
round(1234.1234, 2) ⇒ 1234.12
<aside> 💡 보통은 반올림round 보다는 잘라냄 길이가 음수면, 해당 자리에서 반올림
</aside>
<aside> 💡 dual 테이블 : 간단한 연산 돌아갈 수 있게끔 하는 가상의 테이블
</aside>
문자 함수
<aside> 💡 다른 곳에서도 replace처럼 값을 바꿀 수 있지만 SQL이 제일 빠름 SQL > 서버 > 프론트
</aside>
<aside> 💡 count, substr은 많이 쓰임
</aside>
문자열 뽑아내기
strsub(문자, 시작 위치, 길이)
left(문자, 길이)
right(문자, 길이)
날짜, 시간 함수
<aside> 💡 date 형식 바꾸는 등 날짜 함수 자주 쓰임 데이터베이스에서 서버 혹은 프론트에 던져줄 때 시스템에 fit하게 맞춰서 던져줘야 함!
</aside>
DATE_FORMAT
SELECT DATE_FORMAT(hire_ymd, '%Y-%m-%d')
FROM T ;
DATEDIFF(날짜1, 날짜2)
일 수 차이
날짜1 - 날짜2 이므로 순서 유의하기
So, 나중날짜 - 처음날짜 여야 양수
null 값 처리
null 값은 비교 연산자로 비교가 불가능함
null 값 연산 → null 값 반환
집계 함수 사용 시 주의!!
null이 포함된 행은 집계에서 아예 빠짐
해당되는 행이 하나도 없을 경우, sum, avg 함수의 결과는 null
count 함수의 결과는 0
IFNULL
SELECT IFNULL(freezer_yn, 'N') as freezer_yn
행 번호 출력
내장 함수는 아니지만 자주 사용 됨 → 요새는 interval이 생겨서 잘 안 씀
변수 이름 앞에 @ 기호 붙이며, 치환 문에는 set과 := 기호 사용
자료 일부분만 확인하여 처리할 때 유용
SET @seq:=0;
SELECT (@seq:=@seq+1) 순번,
custid,
name,
phone
FROM customer
WHERE @seq < 2;
<aside> 💡 seq 요새는 자주 안 쓰임
</aside>
CASE WHEN
SELECT CASE WHEN 조건 THEN 참값 ELSE 거짓값 END
SELECT case when DATEDIFF(end_date, start_date) + 1 >= 30 then '장기 대여'
else '단기 대여' END as rent_type
FROM car_rental_company_rental_history
WHERE start_date like '2022-09%'
ORDER BY history_id DESC;
<aside> 💡 AS 생략 가능
</aside>
Section 02. 부속질의
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의
조인보다 필요 데이터만 찾아서 공급하는부속질의가 성능 더 good
주질의 (main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성
스칼라 부속질의 - SELECT 부속질의
부속질의 결과는 단일 행, 단일 열의 스칼라 값 반환
스칼라 값이 들어갈 수 있는 모든 곳에 사용 o
일반적으로 SELECT문, UPDATE SET절에서 사용
주질의, 부속질의 관계는 상관/비상관 모두
SELECT custid,
(SELECT name
FROM customer cs
WHERE cs.custid=od.custid),
SUM(saleprice)
FROM orders od
GROUP BY custid;
인라인 뷰 - FROM 부속질의
부속질의 결과는 다중 행, 다중 열이어도 됨
다만, 가상의 테이블인 뷰 형태 → 상관 부속질의 사용은 x
SELECT cs.name,
sum(od.saleprice) total
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) cs,
orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
중첩 질의 - WHERE 부속질의 = 술어 부속질의
SELECT orderid,
saleprice
FROM orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM orders);
Section 03. 뷰
하나 이상의 테이블 합하여 만든 가상의 테이블
뷰 장점
- 편리성, 재사용성 : 자주 사용되는 복잡한 질의 미리 정의
- → 복잡한 질의 간단 작성
- 보안성 : 필요 데이터만 선별해서 보여줌, 중요한 질의 암호화o
- → 개인정보(주민번호) 등 민감한 정보 제외한 테이블 만들어 사용
- 독립성 : 미리 정의된 뷰를 일반 테이블처럼 사용 → 편리, 사용자가 필요한 정보만 가공
- → 원본 테이블 구조가 변해도 영향 x = 논리적 독립성 제공
뷰의 생성
CREATE VIEW 뷰이름 [열이름, , , ]
AS SELECT ~ FROM ~ WHERE ~
CREATE VIEW vw_customer
AS SELECT *
FROM customer
WHERE address LIKE '%대한민국%';
뷰의 수정
CREATE OR REPLACE VIEW vw_customer (custid, name, address)
AS SELECT custid, name, address
FROM customer
WHERE address LIKE '%영국%';
<aside> 💡 뷰는 수정 잘 안 함
</aside>
뷰의 삭제
04. SQL 고급
Section 01. 내장 함수
숫자 함수
SELECT ABS(-343)
FROM dual;
SELECT ROUND(4.875, 1)
FROM Dual;
반올림
round(1234.12) ⇒ 1234
round(1234.1234, 2) ⇒ 1234.12
<aside> 💡 보통은 반올림round 보다는 잘라냄 길이가 음수면, 해당 자리에서 반올림
</aside>
<aside> 💡 dual 테이블 : 간단한 연산 돌아갈 수 있게끔 하는 가상의 테이블
</aside>
문자 함수
<aside> 💡 다른 곳에서도 replace처럼 값을 바꿀 수 있지만 SQL이 제일 빠름 SQL > 서버 > 프론트
</aside>
<aside> 💡 count, substr은 많이 쓰임
</aside>
문자열 뽑아내기
strsub(문자, 시작 위치, 길이)
left(문자, 길이)
right(문자, 길이)
날짜, 시간 함수
<aside> 💡 date 형식 바꾸는 등 날짜 함수 자주 쓰임 데이터베이스에서 서버 혹은 프론트에 던져줄 때 시스템에 fit하게 맞춰서 던져줘야 함!
</aside>
DATE_FORMAT
SELECT DATE_FORMAT(hire_ymd, '%Y-%m-%d')
FROM T ;
DATEDIFF(날짜1, 날짜2)
일 수 차이
날짜1 - 날짜2 이므로 순서 유의하기
So, 나중날짜 - 처음날짜 여야 양수
null 값 처리
null 값은 비교 연산자로 비교가 불가능함
null 값 연산 → null 값 반환
집계 함수 사용 시 주의!!
null이 포함된 행은 집계에서 아예 빠짐
해당되는 행이 하나도 없을 경우, sum, avg 함수의 결과는 null
count 함수의 결과는 0
IFNULL
SELECT IFNULL(freezer_yn, 'N') as freezer_yn
행 번호 출력
내장 함수는 아니지만 자주 사용 됨 → 요새는 interval이 생겨서 잘 안 씀
변수 이름 앞에 @ 기호 붙이며, 치환 문에는 set과 := 기호 사용
자료 일부분만 확인하여 처리할 때 유용
SET @seq:=0;
SELECT (@seq:=@seq+1) 순번,
custid,
name,
phone
FROM customer
WHERE @seq < 2;
<aside> 💡 seq 요새는 자주 안 쓰임
</aside>
CASE WHEN
SELECT CASE WHEN 조건 THEN 참값 ELSE 거짓값 END
SELECT case when DATEDIFF(end_date, start_date) + 1 >= 30 then '장기 대여'
else '단기 대여' END as rent_type
FROM car_rental_company_rental_history
WHERE start_date like '2022-09%'
ORDER BY history_id DESC;
<aside> 💡 AS 생략 가능
</aside>
Section 02. 부속질의
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의
조인보다 필요 데이터만 찾아서 공급하는부속질의가 성능 더 good
주질의 (main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성
스칼라 부속질의 - SELECT 부속질의
부속질의 결과는 단일 행, 단일 열의 스칼라 값 반환
스칼라 값이 들어갈 수 있는 모든 곳에 사용 o
일반적으로 SELECT문, UPDATE SET절에서 사용
주질의, 부속질의 관계는 상관/비상관 모두
SELECT custid,
(SELECT name
FROM customer cs
WHERE cs.custid=od.custid),
SUM(saleprice)
FROM orders od
GROUP BY custid;
인라인 뷰 - FROM 부속질의
부속질의 결과는 다중 행, 다중 열이어도 됨
다만, 가상의 테이블인 뷰 형태 → 상관 부속질의 사용은 x
SELECT cs.name,
sum(od.saleprice) total
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) cs,
orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
중첩 질의 - WHERE 부속질의 = 술어 부속질의
SELECT orderid,
saleprice
FROM orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM orders);
Section 03. 뷰
하나 이상의 테이블 합하여 만든 가상의 테이블
뷰 장점
- 편리성, 재사용성 : 자주 사용되는 복잡한 질의 미리 정의
- → 복잡한 질의 간단 작성
- 보안성 : 필요 데이터만 선별해서 보여줌, 중요한 질의 암호화o
- → 개인정보(주민번호) 등 민감한 정보 제외한 테이블 만들어 사용
- 독립성 : 미리 정의된 뷰를 일반 테이블처럼 사용 → 편리, 사용자가 필요한 정보만 가공
- → 원본 테이블 구조가 변해도 영향 x = 논리적 독립성 제공
뷰의 생성
CREATE VIEW 뷰이름 [열이름, , , ]
AS SELECT ~ FROM ~ WHERE ~
CREATE VIEW vw_customer
AS SELECT *
FROM customer
WHERE address LIKE '%대한민국%';
뷰의 수정
CREATE OR REPLACE VIEW vw_customer (custid, name, address)
AS SELECT custid, name, address
FROM customer
WHERE address LIKE '%영국%';
<aside> 💡 뷰는 수정 잘 안 함
</aside>
뷰의 삭제
04. SQL 고급
Section 01. 내장 함수
숫자 함수
SELECT ABS(-343)
FROM dual;
SELECT ROUND(4.875, 1)
FROM Dual;
반올림
round(1234.12) ⇒ 1234
round(1234.1234, 2) ⇒ 1234.12
<aside> 💡 보통은 반올림round 보다는 잘라냄 길이가 음수면, 해당 자리에서 반올림
</aside>
<aside> 💡 dual 테이블 : 간단한 연산 돌아갈 수 있게끔 하는 가상의 테이블
</aside>
문자 함수
<aside> 💡 다른 곳에서도 replace처럼 값을 바꿀 수 있지만 SQL이 제일 빠름 SQL > 서버 > 프론트
</aside>
<aside> 💡 count, substr은 많이 쓰임
</aside>
문자열 뽑아내기
strsub(문자, 시작 위치, 길이)
left(문자, 길이)
right(문자, 길이)
날짜, 시간 함수
<aside> 💡 date 형식 바꾸는 등 날짜 함수 자주 쓰임 데이터베이스에서 서버 혹은 프론트에 던져줄 때 시스템에 fit하게 맞춰서 던져줘야 함!
</aside>
DATE_FORMAT
SELECT DATE_FORMAT(hire_ymd, '%Y-%m-%d')
FROM T ;
DATEDIFF(날짜1, 날짜2)
일 수 차이
날짜1 - 날짜2 이므로 순서 유의하기
So, 나중날짜 - 처음날짜 여야 양수
null 값 처리
null 값은 비교 연산자로 비교가 불가능함
null 값 연산 → null 값 반환
집계 함수 사용 시 주의!!
null이 포함된 행은 집계에서 아예 빠짐
해당되는 행이 하나도 없을 경우, sum, avg 함수의 결과는 null
count 함수의 결과는 0
IFNULL
SELECT IFNULL(freezer_yn, 'N') as freezer_yn
행 번호 출력
내장 함수는 아니지만 자주 사용 됨 → 요새는 interval이 생겨서 잘 안 씀
변수 이름 앞에 @ 기호 붙이며, 치환 문에는 set과 := 기호 사용
자료 일부분만 확인하여 처리할 때 유용
SET @seq:=0;
SELECT (@seq:=@seq+1) 순번,
custid,
name,
phone
FROM customer
WHERE @seq < 2;
<aside> 💡 seq 요새는 자주 안 쓰임
</aside>
CASE WHEN
SELECT CASE WHEN 조건 THEN 참값 ELSE 거짓값 END
SELECT case when DATEDIFF(end_date, start_date) + 1 >= 30 then '장기 대여'
else '단기 대여' END as rent_type
FROM car_rental_company_rental_history
WHERE start_date like '2022-09%'
ORDER BY history_id DESC;
<aside> 💡 AS 생략 가능
</aside>
Section 02. 부속질의
하나의 SQL문 안에 다른 SQL문이 중첩된(nested) 질의
조인보다 필요 데이터만 찾아서 공급하는부속질의가 성능 더 good
주질의 (main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성
스칼라 부속질의 - SELECT 부속질의
부속질의 결과는 단일 행, 단일 열의 스칼라 값 반환
스칼라 값이 들어갈 수 있는 모든 곳에 사용 o
일반적으로 SELECT문, UPDATE SET절에서 사용
주질의, 부속질의 관계는 상관/비상관 모두
SELECT custid,
(SELECT name
FROM customer cs
WHERE cs.custid=od.custid),
SUM(saleprice)
FROM orders od
GROUP BY custid;
인라인 뷰 - FROM 부속질의
부속질의 결과는 다중 행, 다중 열이어도 됨
다만, 가상의 테이블인 뷰 형태 → 상관 부속질의 사용은 x
SELECT cs.name,
sum(od.saleprice) total
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) cs,
orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
중첩 질의 - WHERE 부속질의 = 술어 부속질의
SELECT orderid,
saleprice
FROM orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM orders);
Section 03. 뷰
하나 이상의 테이블 합하여 만든 가상의 테이블
뷰 장점
- 편리성, 재사용성 : 자주 사용되는 복잡한 질의 미리 정의
→ 복잡한 질의 간단 작성 - 보안성 : 필요 데이터만 선별해서 보여줌, 중요한 질의 암호화o
→ 개인정보(주민번호) 등 민감한 정보 제외한 테이블 만들어 사용 - 독립성 : 미리 정의된 뷰를 일반 테이블처럼 사용 → 편리, 사용자가 필요한 정보만 가공
→ 원본 테이블 구조가 변해도 영향 x = 논리적 독립성 제공
뷰의 생성
CREATE VIEW 뷰이름 [열이름, , , ]
AS SELECT ~
FROM ~
WHERE ~
CREATE VIEW vw_customer
AS SELECT *
FROM customer
WHERE address LIKE '%대한민국%';
뷰의 수정
CREATE OR REPLACE VIEW vw_customer (custid, name, address)
AS SELECT custid, name, address
FROM customer
WHERE address LIKE '%영국%';💡 뷰는 수정 잘 안 함
뷰의 삭제
DROP VIEW vw_customer;'백엔드(Back-End) > DB' 카테고리의 다른 글
| [DB] 05. 데이터베이스 프로그래밍 (2) | 2023.10.19 |
|---|---|
| 03. SQL 기초 (0) | 2023.10.18 |
| 02. 관계 데이터 모델 (1) | 2023.10.18 |
| 01. Database (0) | 2023.10.18 |



